Paper Notes: Efficient Memory Management for Large Language Model Serving with PagedAttention
Notes for my future self while reading the paper
Summary
Problem: Limiting batch size of LLM serving requests because memory used in key-value cache of LLMs is prone to fragmentation and duplication due to ineffective memory management.
Solution: the paper proposed PagedAttention algorithm inspired by OS virtual memory and paging techniques.
Implementation: building a LLM serving system vLLM on top of PagedAttention.
Goal:
near-zero waste in KV cache memory
flexible sharing of KV cache within and across requests
Eval: improved throughput of popular LLMs by 2-4x with same latency compared to state-of-the-art systems (FasterTransformer, Orca).
Intro

Memory Challenges in LLM Serving
Large KV cache
Complex decoding algos
Scheduling for unknown input & output lengths
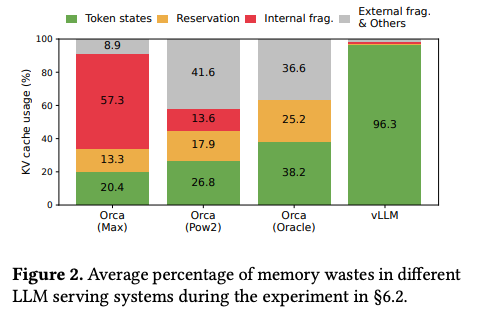
Figure 2
only 20% - 38% of KV cache memory is used to store actual token states in existing systems.
inefficient memory management causes less memory for token states → decreases LLM serving request batch size.
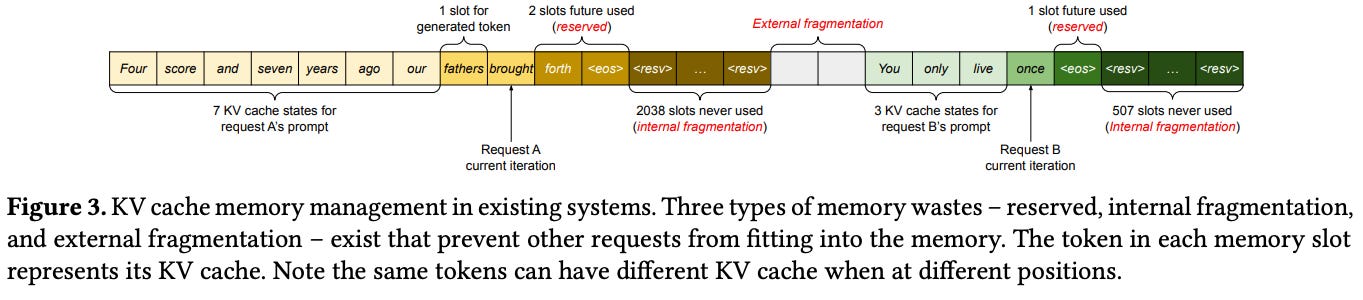
Figure 3
chunk pre-allocation schema in existing systems has 3 source of mem wastes
reserved slots
internal fragmentation
external fragmentation
Method
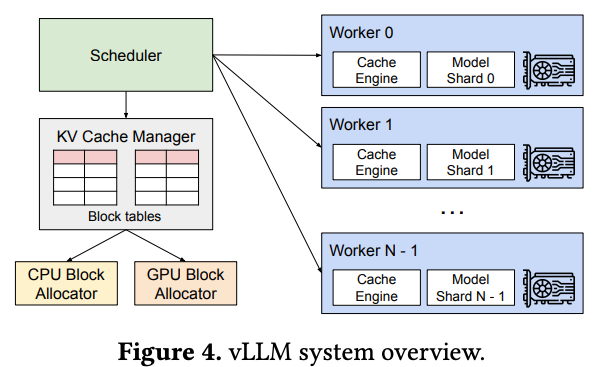
Figure 4 vLLM architecture
centralized Scheduler: coordinate execution of distributed GPU workers.
KV cache manager manages KV cache in pages for PagedAttention (manages physical KV cache mem on GPU workers through instructions sent by centralized scheduler).
PagedAttention
Problem: memory fragmentation in serving LLMs.
Solution: inspired by Operating System Paging. Allowing KV Cache for a sequence to be stored in non-contiguous physical memory blocks.
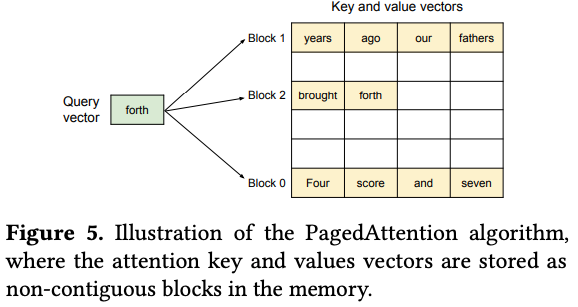
Partitioning: KV cache for each sequence is divided into fixed-size units called KV blocks. Each block holds the key and value vectors for a set number of tokens.
Non-Contiguous Storage: These KV blocks do not need to be stored next to each other in physical GPU memory (Figure 5).
Modified Attention Kernel: The attention computation kernel is adapted.
Instead of operating on one large contiguous tensor, it fetches the required KV blocks individually based on the current query token.
It performs attention calculations block-wise (computing scores using keys from a block, then applying scores to values from the same block) before combining the results.
Result: PagedAttention allows flexible, paged memory management for KV cache by breaking requirement for contiguous storage. → more efficient mem management.
KV Cache Manager
Goal: design KV Cache Manager - mem mgmt system for PagedAttention.
Provides the mechanism for flexible, paged memory management.
Decouples the logical view of the sequence from the physical memory layout.
Reduces memory waste (fragmentation, reservation).
Key Concepts:
Logical Blocks: Represent a request's KV cache as a sequence of logical blocks (conceptually contiguous, representing token positions).
Physical Blocks: Fixed-size chunks of actual GPU DRAM managed by a block allocator. Can be non-contiguous.
Block Tables (Mapping): core item, maintains tables mapping logical blocks (per request) to physical blocks (in GPU memory). (Fig 6)
Allocation Strategy:
Dynamic & On-Demand: Physical blocks are allocated only when needed as a sequence generates new tokens and fills existing blocks.
No Large Pre-allocation: Avoids reserving huge chunks for max sequence length, unlike traditional systems.
Decoding with PagedAttention and vLLM
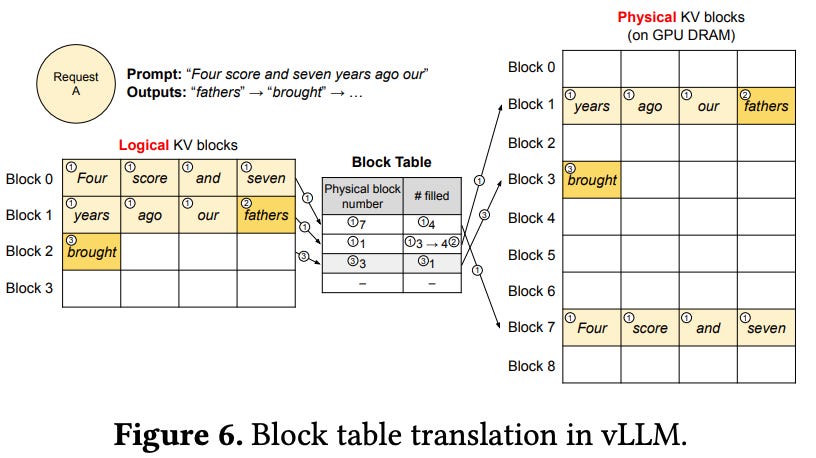
vLLM does not require reserving memory for the max possible generated sequence length initially. Instead, is reserved only the necessary KV blocks to store the KV cache generated during prompt computation.
in first decoding step, vLLM generates new token with PagedAttention algo on physical blocks 7 and 1.
in the second decoding step, vLLM stores new KV cache in a new logical block. It alloc a new physical block 3 for it and stores this mapping in Block Table.
Scheduling and Preemption
Context:
Request traffic can exceed the system processing capacity in LLM serving.
Requests have highly variable input prompt lengths, and their output lengths (number of generated tokens) are unknown beforehand and depend on the input and the model.
vLLM relies on GPU memory to store the dynamically growing KV cache for active requests.
Problem:
vLLM can run out of physical GPU memory blocks to store the new KV cache.
Need design decisions like in Operating Systems
Eviction: Which ongoing or waiting requests should be preempted to free up memory?
Recovery: How can the state (KV cache) of these preempted requests be restored when they are rescheduled later?
Distributed Execution
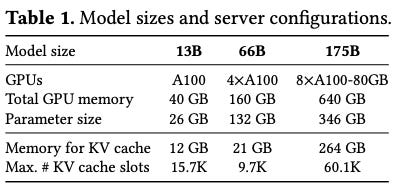
LLMs parameter size > single GPU mem → partition across distributed GPUs and execute them in parallel → a memory manager of distributed memory.
What happens in one iteration?
scheduler prepares message with input token IDs for each request in the batch and the block table for each request.
scheduler broadcasts this control message to GPU workers.
GPU workers start to execute model with input token IDs.
in attention layers, GPU workers synchronize intermediate results with all-reduce communication primitive without coordination of scheduler.
GPU workers send sampled tokens of this iteration back to scheduler.
→ GPU workers do not need to synchronize on memory management as they only need to receive all mem management info at the beginning of each encoding iteration with step inputs.
